

Seedance 2.0提示词体系课:搭建一套属于自己的视觉语言系统(万字收藏版)
 2203
2203
系统学习运营课程,加入《91运营网VIP会员》,开启365天运营成长计划>>
|
说实话,即梦Seedance 2.0的理解能力真的强到有点离谱。 真正做到了,简单一两句话,出来的质量也不会太差。 不需要什么专业术语,不需要长篇大论,就几句自然语言,它就懂了。 从这个角度来说,提示词确实已经不是门槛了。 大部分场景下,你用日常说话的方式告诉它你想要什么,它都能给你一个至少七八十分的结果。 这就是Seedance2.0的厉害之处。 但我想说的是,更确定性的好,还是随机性的好,其实是两码事。 而且随机性的结果,会带来一个问题,就是“抽卡”。 也许你“抽中”的视频质量不错,但不一定是你想要的。 为什么会这样? 问题就出在了:你跟AI之间,差了一套语言。 当你说”高级感”,AI其实是不知道”高级”在视觉上到底长什么样。 想说”柔和的光”,AI也只是把光均匀地糊上去。 很多人爱跟AI说”电影感”,实际上AI调出来的,是一个见得最多的默认模板。 它不是不听话,它是真的不知道你具体想要什么。而在摄影和灯光行业里,这些东西是有精确语言的。 景别、焦段、光圈控制空间感;光线方向、衰减路径、反射填充控制光影层次;色温、色相分布、明暗比例控制色彩情绪。 这些倒不是什么高深概念,而是影视行业这么多年积累下来的一套视觉控制语言。 假如说我们把自己当作AI视频导演,那么,搭建自己的视觉语言系统,其实也只是为了,让AI这个“摄影师”更好地工作。 第一章 认知基础:理解AI的视觉语言逻辑1.1 从”描述”到”指令”的思维转换很多人写提示词的第一个困境,不是词汇量不够,而是思维方式错了。 你觉得自己在跟AI对话,其实AI根本没在”听”你说话。 你输入的每一个词,AI做的是拿它去匹配训练数据里的特征组合。 这就导致了一个根本性的差异:
写提示词的第一步,不是学会”描述”得更好看,而是要懂得切换思维。 1.2 AI的三个常见行为理解了上面这一点之后,你还需要知道AI有三个常见的”坏习惯”: 它会偷懒。 为了计算效率,AI会自动弱化它认为不重要的部分。提示词写了十个元素,后面四五个可能全被简化了。所以你经常发现提示词越长,后半段越不生效。 它会套模板。 发现你写的风格词它见过很多次,就直接调用训练数据里最典型的搭配。这就是为什么一加”电影感”,出来的图长得都差不多。 它会自己脑补。 你在提示词里没有覆盖到的部分,AI不会留白,它会自动从训练数据里调用最常见的默认搭配来填上去。没定义的光线、没限定的表情、没指定的构图,全部会被AI的默认值覆盖。 1.3 提示词的本质:约束AI的自由度提示词做的,不是给AI灵感,而是给AI圈定一个“摄影”空间。 你什么都不写的时候,AI的生成空间无限大,结果完全随机——就是大家说的”抽卡”。 你每写一个有效的词,就是在某个维度上压缩AI的选择空间:
写得越具体、越准确,AI能乱发挥的空间越少。 但前提是:你压缩的必须是”有效维度”。 “高级感”"电影感”这种词,你觉得好像是在限制AI,但实际上啥也没限制住,AI的自由度跟没写一样大。 核心就一句话:写提示词不是做加法,是做减法——减掉AI的自由度,只留下你要的那条路。 换句话说,就是给提示词降噪,AI才能更容易听到你真正想要的画面。 第二章 提示词核心方法论2.1 提示词结构公式:主体→光影→氛围提示词有一个最基本的骨架——三段式:
简单记:主体稳、光影准、氛围自然。 顺序别搞反了。 2.2 精简的艺术:减情绪词、减重复词、减叙述句对大部分人来说,提示词写得越多,错得越多。真正让画面变好的不是加东西,而是砍东西。 第一刀,砍情绪词。 “高级感”"电影感”"唯美感”,对AI来说不是有效控制信息。 你现在写这些词出来效果还行,是因为模型变聪明了,不是词变精准了。 AI只是从大量可能里给你一个凑合的结果,本质还是抽卡。 第二刀,砍重复词。 “电影感”"大片氛围”"高级质感”,你感觉在加强,AI觉得你在重复。 这些相似的词不会叠加效果,只会分散权重。 每条信息只出现一次就够。 第三刀,砍叙述句。 “她轻轻推开门,走进洒满阳光的房间”,很有画面感,但AI不是在读小说。 它会把这段话拆成一堆零散的动作标签,没有主次。 提示词不要去写故事,而要写结构:
拆清楚就够了。 2.3 抽象词具象化:把”感觉”翻译成”参数”这一部分是整套方法论的核心。 你脑子里有感觉,但AI不懂感觉。 “梦幻”"孤独”"压抑”在AI眼里只是一个模糊的语义标签,它不知道这些词对应什么画面,只能猜。 解决方法只有一个: 把抽象感觉翻译成AI能执行的视觉参数。 看一个例子:
其他常见抽象词的翻译:
当你把抽象词拆成参数,画面就不再靠运气了。 2.4 负面提示词的分层策略告诉AI”你不要什么”,和告诉它”你要什么”同样重要。 负面提示词不是把不想要的东西全塞进去就完了——它是分层的:
三层从底到高叠加,AI的发挥空间被逐层压缩,输出越来越稳定。 第三章 摄影语言:让AI像摄影师一样工作3.1 景别与心理距离的对应关系很多人在提示词里只描述内容——有什么人、什么场景。但你忽略了一个关键信息:镜头。 你不是在告诉AI”画面里有什么”,而是要试着告诉AI”这个画面怎么被拍出来的”。 景别决定的不是画面大小,而是观众和画面之间的心理距离:
在提示词里写清楚景别,AI画面立刻就有”拍摄感”,而不是一张”AI生成的图”。 3.2 焦段、光圈与空间感控制景别决定拍多远,焦段和光圈决定怎么拍。 焦段改变的不是清晰度,是透视结构:
光圈控制虚化程度:
在提示词里加上焦段和光圈值,AI自己就会按真实摄影逻辑来生成。 3.3 构图原则:位置、动线、平衡构图的本质是给观众的视线规划路线。 主体位置 — AI默认用中心构图,安全但平淡,也是”AI味重”的常见原因。三分法偏移主体,画面立刻有呼吸感。 视觉动线 — 什么都不写,观众视线就是散的。在提示词里写清楚动线方向,AI就会顺着逻辑安排元素。 画面平衡 — 平衡不等于对称。靠颜色深浅、明暗对比、物体体量来分配视觉重量,不对称也能显得稳。 来看同一个意图在不同构图下的写法:
同一个想法,不同构图,画面完全不是一个级别。 第四章 光线与色彩:画面的灵魂密码4.1 光线控制:方向、层次、衰减、反射光线是AI画面最容易露馅的地方。你觉得”假”但说不出来哪里假,十有八九是光线的问题。 光线的控制是四层递进逻辑: 方向 → 不能只写”柔和光线”。 要写光从哪个方向进来、阴影落在哪里、阴影边缘是硬还是软。方向定了,画面就有立体感。 层次 → AI默认把画面照得很满很均匀。 你要明确:主光在哪、补光多弱、暗部保留多少。光线有主次,情绪才有落点。 衰减 → AI不通过”亮度”理解光线,而是通过衰减路径推导亮度分布。 “柔光”"弱光”这些感觉词基本没用。你要写:光照亮了哪个区域、在哪里开始减弱、在哪里消失。AI会根据这条路径自动拉开明暗差。 反射 → 真正让空间真实的不是直射光,而是光经过多次反射慢慢填亮空间。 写”光打到墙面被反射,反射光填充人物暗部”——写不写这一层,是”还行”和”很真实”之间的分水岭。 另外还有一个进阶概念——体积光。 光穿过空气中的微粒才会被看见(雾气里的光束、窗帘缝隙的光柱),写清楚”光从哪来、穿过了什么介质、形成怎样的光束”,氛围感直接拉满。 4.2 室内光与室外光的写法差异写不好室内光线,是因为你在套室外光的写法,但在AI眼里这两套逻辑完全不同。 室外光源默认是太阳,不用声明。 但室内光不可能凭空出现——你不给光源实体,AI就自己瞎编一个,光线肯定假。 室内写光的正确链路:光源实体 → 衰减路径 → 反射填充
核心记住一点:室内光的重点不是”亮度控制”,而是你有没有把这个空间的光照逻辑讲清楚。 4.3 色彩参数化:从直觉到数据“给我某某色彩风格”——AI收到的只是一个标签,只能猜。 要把审美直觉翻译成AI能执行的色彩数据,搞清楚三件事:
不要写”梦幻的蓝紫色调”,写”主色: 低饱和度冷蓝,辅色:微弱暖粉,去除绿色和黄色干扰”。 AI对参数级描述的执行力度完全不是一个量级。 第五章 人物与动态:从静止到生动5.1 皮肤质感与微表情人物是AI最容易露馅的地方,露馅最多的两个位置:皮肤和表情。 皮肤的关键——当材质写,不当效果写。 AI默认把皮肤当”需要被优化的视觉效果”来处理,拼命叠光泽、叠磨皮,结果就是油腻感。 正确做法:
微表情的关键——三个要素缺一不可:
比如”害羞”:不只是脸红,还有轻微低头、视线闪避、手指无意识揪衣角。 加上身体动作依托,AI才会构建完整姿态链,画面才脱离摆拍感。 5.2 动作提示词的正确写法动作是另一个重灾区。堆动词看起来详细,但对AI来说是指令冲突。 核心原则:
看一个具体对比:
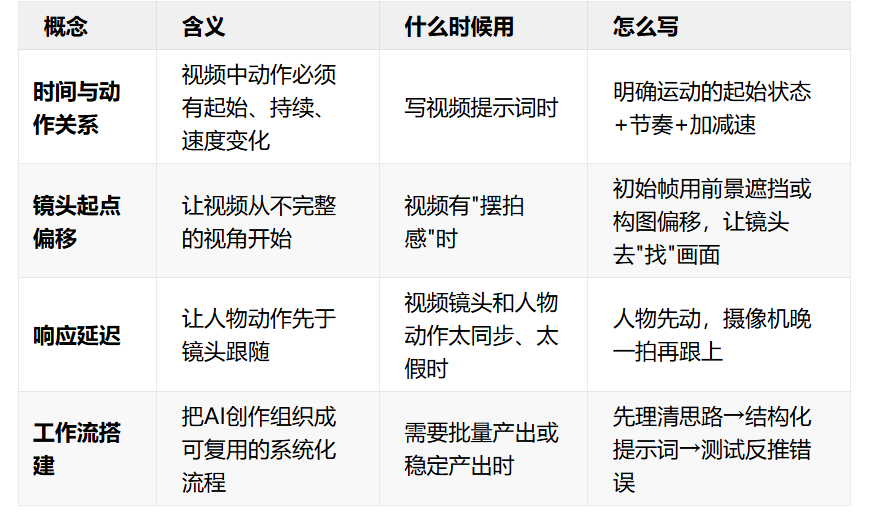
主次分明,画面就干净利落。 第六章 工作流与分镜:系统化创作6.1 AI视频的时间逻辑与运动结构AI视频不是”动起来的图片”,底层逻辑完全不同。 静态图只要一个瞬间,视频是时间中的连续运动。 只写”人物向前走去”,AI能动,但会非常僵硬——它没有得到任何运动节奏的信息。 视频提示词必须明确的:
消除摆拍感的核心策略:
核心理念:消除摆拍感不是让画面更复杂,而是让镜头变得”不那么聪明”。当你允许画面不完美,AI的假感才会消失。 6.2 工作流搭建的正确顺序很多人搭工作流的第一步就错了——上来就写提示词,不断试错,流程越长效果越乱。 正确顺序是反过来的:
会搭工作流的人不是靠运气,而是靠复盘。 当你把AI创作从”碰运气”变成一套有逻辑的流程,才算真正掌握了这个工具。 6.3 分镜提示词常规写视频提示词的方式是:一整段话从头描述到尾,”人物从左边走进来,看了看四周,然后坐下,镜头慢慢推近”。 写得很完整,但交给AI之后,画面的节奏、镜头的切换、每一秒具体展示什么,全部由AI自己决定。 这种情况下,AI确实做出来了,但节奏是均匀铺开的,没有轻重缓急。 分镜解决的就是这个问题: 你来决定每一秒在发生什么,镜头怎么走,画面看什么,怎么过渡到下一段。 分镜提示词的四个底层要素: 不管用哪种分镜写法,底层都是在回答四个问题:
四个要素缺任何一个,那一段分镜就交给了AI的默认行为。 镜头动作的常用词汇: 这些是分镜写作中最高频的镜头控制词,写分镜时直接调用:
四种分镜写法,看场景选用: 第一种:时间码式分镜 按秒数把视频切成段落,每一段写明时间范围和对应画面。 结构:
适合:广告、产品展示、MV——任何对节奏要求严格的场景。时间码让AI对每一段的时长有精确预期,节奏最可控。 第二种:镜头叙事式分镜 不用秒数,用镜头动作的自然切换来划分段落。 结构:
适合:故事片、剧情向视频、动作场景。不锁定具体秒数,让AI根据动作的自然节奏来分配时间,更灵活,但节奏控制力比时间码式弱一些。 第三种:时间码参考图 先准备好每一段对应的参考图,提示词里用时间码 + @参考图 + 镜头动作三合一。 结构:
适合:需要每一格画面都精准匹配预设风格的场景。控制力最强,但准备工作最多——你需要先有分镜图。好消息是,分镜图本身可以用AI图片生成工具来制作。 第四种:九宫版参考图 前三种写法都需要你在提示词里写清楚每一段的细节。 但Seedance 2.0的多模态理解能力确实强大,就是实在不想学那么概念,写那么多话,你可以用九宫图分镜。 做法:
九宫格本身携带了大量信息,构图、色彩、角色造型、场景变化、景别——这些全部由图片传达,不再需要你逐一用文字描述。 Seedance 2.0会自动从画面中提取视觉逻辑,你的一句话只需要告诉它顺序和基调。 九宫图分镜 vs 详细文字分镜,怎么选?
大部分日常创作,九宫图分镜已经足够。 只有当你对节奏要求非常严格(比如商业广告卡点、MV),才需要用详细文字分镜去逐秒控制。 转场方式速查: 分镜写的是每一段”在发生什么”,但段和段之间”怎么过渡”同样影响成片质量。
不写转场方式,AI默认硬切。 硬切不一定差,但如果你的视频需要流畅感或情绪过渡,主动指定转场方式差别很大。 分镜的本质是什么? 不是把视频切碎,而是把你对每一秒的控制意图写清楚。 没有分镜的提示词,AI在规定时间里自己安排所有事情,你只能看最终结果满不满意。 有分镜的提示词,你规定了第几秒看什么、镜头怎么动、怎么过渡到下一段——AI只负责在你画好的框架里填充画面。 控制力的差别,就是”碰运气”和”按计划出片”的差别。 附录:AI提示词核心概念速查手册A. 情绪与氛围类
B. 光线与色彩类
C. 摄影与构图类
D. 人物与动作类
E. 进阶机制类
F. 视频与工作流类
|


扫码加入91运营社群










近期文章
- 删了好友后,朋友圈里的点赞评论还在吗? 2026年7月12日
- 几个私藏的核心干货 2026年7月12日
- 靠平台低价会员,年入百万 2026年7月12日
- 请查收!小红书运营全流程! 2026年7月12日
- 2026视频号教培直播带货全流程:5步法+3玩法+避坑指南! 2026年7月12日
- 微信豆、ADQ和小店推广有啥区别?你适合用什么投流方式? 2026年7月12日
- 视频号0-1如何起号?有什么投流技巧? 2026年7月12日
- 谭木匠:弱弱的小生意如何做成高利润的强品牌? 2026年7月12日
- 短视频获客攻略:同城引流爆款文案30条!谁拍谁有流量! 2026年7月12日
- 2026年新手本地直播活动策划方案全流程细节含案例! 2026年7月12日